# devtools::install_github('mattroumaya/doubleheadr')
library(doubleheadr)
survey_data <- doubleheadr::demo
survey_data_preserve <- doubleheadr::demo
SurveyMonkey 🐒 is a popular online survey development software that outputs a very frustrating kind of response file. If you’ve ever received exported results from SurveyMonkey, you probably know what I’m talking about.
When response data is exported as a .csv or .xlsx file, it looks something like this:
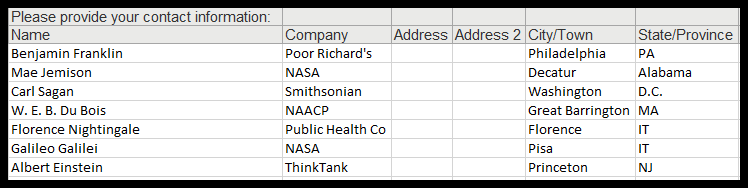
You can see that the response data for the question “Please provide your contact information:” contains several inputs for Name, Company, Address, etc. Deleting the first row might seem to make sense at first, but when your survey contains dozens of questions with multiple question types, things can get out of hand really fast.
This post is an overview of one approach for cleaning up SurveyMonkey columns. I struggled with this for a while, but now have a workflow that seems pretty efficient, especially if your goal is to set up RMarkdown reports while your survey is being administered. If it is helpful for you, that’s awesome! If you have a better way of approaching this issue, please let me know!
The workflow
- A function that creates column names that are concatenated from the question + response in_snake_case (or camelCase, or whatever) using the aptly-named
janitorpackage.
- Cleaning up any annoying/extremely_long_column_names_from_very_long_questions.
- If needed, subsetting columns into dataframes or lists for analyses/visualization. (The
dplyrfunctionsstarts_withandends_withwork really well with this workflow).
- That’s it, now you’re ready to do some meaningful analyses!
Let’s start by viewing our response data. You’ll need to use the packages tidyverse, janitor, and readxl if you’re using .xlsx.
(I always save the original version without any changes so I can build in QC checks, and tend to use _preserve as an identifier.) You’ll see that some columns are missing values, and will be read in with “…#”
**Edit in 10/2022: I’ve added sample data to avoid loading .csv/.xlsx files. You can grab it by running:
survey_data %>%
head(4) %>%
gt::gt()| Respondent ID | Please provide your contact information: | ...3 | ...4 | ...5 | ...6 | ...7 | ...8 | ...9 | ...10 | ...11 | I wish it would have snowed more this winter. |
|---|---|---|---|---|---|---|---|---|---|---|---|
| NA | Name | Company | Address | Address 2 | City/Town | State/Province | ZIP/Postal Code | Country | Email Address | Phone Number | Response |
| 11385284375 | Benjamin Franklin | Poor Richard's | NA | NA | Philadelphia | PA | 19104 | NA | benjamins@gmail.com | 215-555-4444 | Strongly disagree |
| 11385273621 | Mae Jemison | NASA | NA | NA | Decatur | Alabama | 20104 | NA | mjemison@nasa.gov | 221-134-4646 | Strongly agree |
| 11385258069 | Carl Sagan | Smithsonian | NA | NA | Washington | D.C. | 33321 | NA | stargazer@gmail.com | 999-999-4422 | Neither agree nor disagree |
Ugh! Look at those terrible column names. 😠

double_header <- function(x) {
df <- as_tibble(x)
keydat <- df %>%
slice(1) %>%
select_if(negate(is.na)) %>%
pivot_longer(everything()) %>%
group_by(grp = cumsum(!startsWith(name, "..."))) %>%
mutate(value = sprintf("%s (%s)", first(name), value)) %>%
ungroup %>%
select(-grp)
df <- df %>%
rename_at(vars(keydat$name), ~ keydat$value) %>%
slice(-1) %>%
clean_names()
}The double header breakdown
slice(1)selects the first row, which contains the other names we need.
select_if(negate(is.na))selects all columns where the first row is notNA, because we don’t need to alter these column names.
pivot_longer(everything())transforms our dataframe from wide to long, and automatically creates the columnsnameandvalue.
- (
nameholds all of our column names andvalueholds all of our secondary column names.)
# A tibble: 6 × 2
name value
<chr> <chr>
1 Please provide your contact information: Name
2 ...3 Company
3 ...4 Address
4 ...5 Address 2
5 ...6 City/Town
6 ...7 State/Provincegroup_by(grp = cumsum(!startsWith(name, "...")))groups rows and then applies a cumulative sum for all rows in thenamecolumn that do not start with “…” until a row other than “…” is encountered. This is better shown in the table below:
| name | value |
|---|---|
| 1 | |
| Please provide your contact information: | Name |
| ...3 | Company |
| ...4 | Address |
| ...5 | Address 2 |
| ...6 | City/Town |
| ...7 | State/Province |
| ...8 | ZIP/Postal Code |
| ...9 | Country |
| ...10 | Email Address |
| ...11 | Phone Number |
| 2 | |
| I wish it would have snowed more this winter. | Response |
mutate(value = sprintf("%s (%s)", first(name), value))updates ourvaluecolumn and concatenates our names so that they’re meaningful. We’re almost there!
| name | value |
|---|---|
| 1 | |
| Please provide your contact information: | Please provide your contact information: (Name) |
| ...3 | Please provide your contact information: (Company) |
| ...4 | Please provide your contact information: (Address) |
| ...5 | Please provide your contact information: (Address 2) |
| ...6 | Please provide your contact information: (City/Town) |
| ...7 | Please provide your contact information: (State/Province) |
- Then we just
ungroupand drop thegrpcolumn.
- Finally, we rename the columns in our
survey_databy using our updated names inkeydat$value, and callclean_names()to convert to snake_case 🐍
All together now
Let’s run the function on survey_data
survey_data <- double_header(survey_data)Here’s a comparison of our original names and our cleaned names:
| Old Names | New Names |
|---|---|
| Respondent ID | respondent_id |
| Please provide your contact information: | please_provide_your_contact_information_name |
| ...3 | please_provide_your_contact_information_company |
| ...4 | please_provide_your_contact_information_address |
| ...5 | please_provide_your_contact_information_address_2 |
| ...6 | please_provide_your_contact_information_city_town |
| ...7 | please_provide_your_contact_information_state_province |
| ...8 | please_provide_your_contact_information_zip_postal_code |
| ...9 | please_provide_your_contact_information_country |
| ...10 | please_provide_your_contact_information_email_address |
| ...11 | please_provide_your_contact_information_phone_number |
| I wish it would have snowed more this winter. | i_wish_it_would_have_snowed_more_this_winter_response |
Subsetting made easy!
Now if we want to subset data based on certain questions/columns, we can do it really easily using starts_with and ends_with.
Sometimes it’s easier to rename columns so that they’re shorter and easier to work with, and sometimes it’s fine to keep some really long column names if your survey contains a lot of similar questions.
Below, we’ll combine all of the questions that start with please_provide_your_contact_information and shorten the names to only start with contact_information + value.
starts_with example:
contact_info <- survey_data %>%
select(starts_with("please_provide_your_contact_information")) %>%
rename_at(vars(starts_with("please")), ~str_remove(.,"please_provide_your_"))
contact_info %>%
head() %>%
gt::gt()| contact_information_name | contact_information_company | contact_information_address | contact_information_address_2 | contact_information_city_town | contact_information_state_province | contact_information_zip_postal_code | contact_information_country | contact_information_email_address | contact_information_phone_number |
|---|---|---|---|---|---|---|---|---|---|
| Benjamin Franklin | Poor Richard's | NA | NA | Philadelphia | PA | 19104 | NA | benjamins@gmail.com | 215-555-4444 |
| Mae Jemison | NASA | NA | NA | Decatur | Alabama | 20104 | NA | mjemison@nasa.gov | 221-134-4646 |
| Carl Sagan | Smithsonian | NA | NA | Washington | D.C. | 33321 | NA | stargazer@gmail.com | 999-999-4422 |
| W. E. B. Du Bois | NAACP | NA | NA | Great Barrington | MA | 1230 | NA | dubois@web.com | 999-000-1234 |
| Florence Nightingale | Public Health Co | NA | NA | Florence | IT | 33225 | NA | firstnurse@aol.com | 123-456-7899 |
| Galileo Galilei | NASA | NA | NA | Pisa | IT | 12345 | NA | galileo123@yahoo.com | 111-888-9944 |
ends_with is really helpful in combination with our double_header function and SurveyMonkey data, because open-ended or free-text responses all end with …open_ended_response
Depending on the report or project you’re building, it’s sometimes useful to add all of your free-text responses as dataframes in a list, to include as an appendix, or to select important comments to include in an executive summary.
ends_with example:
open_ended <- survey_data %>%
select(ends_with("response"))
print(names(open_ended))[1] "i_wish_it_would_have_snowed_more_this_winter_response"That’s it for this post! I’d love to hear from you if you found this workflow helpful, or if there is any way it could be improved.
Some ideas for future posts include building this function into a package (for the sole purpose of learning how to build R packages), showing a few tricks I’ve learned with the HH and lattice packages for visualizing Likert scale responses, and some more trivial posts about Rummy, House Hunters, and any other reality TV my wife and I are currently fixated on.